
 We’d all like to save money with shared hosting, but for some websites, VPS or even dedicated plans are unavoidable. If you do end up having to spring for a more advanced plan, it probably means your site is getting bigger and receiving more traffic – so the financial cost will be worth the rewards. But how can you plan for that financial cost, and minimize it as much as possible? To start, you need to know where your site is headed. To figure out the best budget for your web hosting plan, it’s important to first identify the specific goals that you have for your site. You don’t want to end up committing to a plan that doesn’t fit those goals, whether it’s too complex or not scalable enough.
We’d all like to save money with shared hosting, but for some websites, VPS or even dedicated plans are unavoidable. If you do end up having to spring for a more advanced plan, it probably means your site is getting bigger and receiving more traffic – so the financial cost will be worth the rewards. But how can you plan for that financial cost, and minimize it as much as possible? To start, you need to know where your site is headed. To figure out the best budget for your web hosting plan, it’s important to first identify the specific goals that you have for your site. You don’t want to end up committing to a plan that doesn’t fit those goals, whether it’s too complex or not scalable enough.
What are your site goals?
To figure out the best budget for your web hosting plan, it’s important to first identify the specific goals that you have for your site. You don’t want to end up committing to a plan that doesn’t fit those goals, whether it’s too complex or not scalable enough.
If you’re aiming for your website to…
- Attract a small following among family and friends
- Serve as a point of contact for a local business
- Promote an individual portfolio or CV
…then shared hosting ($2.75 – $15.00/month) will be more than sufficient. But if you want that website to:
- Handle the traffic demands of a medium-sized business
- Be secure enough to handle electronic card payments
- Accommodate the files of a successful and active blog
- Maintain good page speed and image loading times as traffic increases
…you’ll need to upgrade to VPS ($5 – $80/month).
The only websites that will need to shell out for a dedicated plan ($80 – $730/month) are:
- Pages for companies with a huge, multinational audience that generates a lot of traffic
- Sites with particularly large ecommerce demands, like storing lots of high-res product images
If you’re running a small website with only a few pages right now, but the goal is to eventually scale up and become a high-traffic, content-heavy platform, then it’s possible to keep that ambition while saving your money – after all, you can always upgrade to a VPS or dedicated plan later.
Basically, you can think of shared, VPS, and dedicated hosting as the respective options for small, medium, and large websites. Once you’ve chosen between these types, the real budgeting work begins.
Planning costs by the year
The most important factor in a web hosting budget is time commitment. When you sign up to a hosting plan, you’ll have the option to pay for anywhere between one month and four years in advance.
The incentive to pay for four years up front is that the price per month becomes much lower when you do so. For example, HostGator’s most basic shared plan costs $6.95/month when purchased for three years, $7.95/month for two years, and $8.95/month for one year. It costs $10.95 to purchase one month at a time.
In short, here’s how much you’d pay initially by plan, and how much you’d end up paying after three years:

By paying for a year up front rather than by the month, you’ll already save $24 after one year, and $72 after three years.
We’d recommend purchasing a plan for one year in advance. That way, you still save on the monthly price, but you’re not sacrificing the opportunity to reach a growth goal and upgrade your plan within a year or two.
Most hosting providers offer money-back guarantee periods that last for the first 30 or so days after purchase, so regardless of how many years you commit to in advance, you’ll still get that initial window risk-free.
It’s also important to note that most hosting providers offer tempting introductory prices for the first purchase period, which then renew at a much higher rate.
For example, buying HostGator’s basic shared plan for one year costs $5.95/month the first year, and then renews at $8.95/month. To buy the same plan for three years costs $2.75/month for the first three years, and then renews at $6.95/month for the following three years.
Choosing a provider
You don’t have to pay top dollar for good service. There are plenty of cheap hosting providers that can support your site without breaking the bank.
If you’re looking for dirt cheap hosting, then Hostinger’s $0.80/month introductory shared price is a good place to start, as is iPage’s $1.99/month shared plan. But if you’re looking to get the most value for your money, then it’s worth taking a closer look.
We’ve talked about how most hosting providers offer introductory prices and free trial periods. But the top providers also have their differences. Firstly, you want to choose a provider that has a good reputation for your chosen hosting type.
For example, while DreamHost offers great features on its shared plans, its VPS plans don’t allow you root access, and you’d be better served elsewhere.
And while Hostinger’s shared plans are secure and user-friendly, it doesn’t offer any dedicated plans, which immediately limits your potential to scale.
Providers also differ in their more general strengths and weaknesses. If you value customer service above all, then DreamHost’s lack of phone support will be a major mark in your “cons” column. If uptime is your top priority, then HostGator’s 99.99% guarantee will be a big draw.
Additional costs
Saving money is important. But it’s also important to make room in your budget for the hosting features that matter most to you. Here are three add-ons that we think are worth paying for:
- Security tools
- Automated backups
The most important security cost you’ll incur is that of an SSL certificate. You can’t really host a successful website without this coveted padlock icon, because it’s an immediate signal to visitors that their data is safe.
Many hosting providers include a basic version of SSL for free on some plans, or you can up your game and purchase a premium SSL certificate for about $50. If you want to take security a step further, you can also budget for SiteLock security at about $2/month, which offers daily malware scans and increased protection from DDoS attacks.
Adding advanced email functionalities to your website will typically cost between $6 and $15/month. Many web hosts will let you purchase business accounts for G Suite or Office 365, which you can then use to set up addresses @yourdomain.com.
This is an especially attractive feature for anyone looking to host a business or eCommerce site.
You can always back up your site yourself. But if you have room in your budget for the convenience of automatic backups, most hosting providers offer this service for around $2/month.
The Wrap-Up
It’s important to have clear goals in mind when you choose a hosting plan. If you’re making a small blog to update family and friends, then there’s no need to overpay for a VPS plan.
But if you’re looking to get an eCommerce business off the ground, then the lack of security on a shared server will be too limiting. Once you know what you want from your site, it will be easy to select a plan that will give you the most value for your money.
Lastly, don’t forget to budget your time wisely, too! You’ll save the most money by purchasing a hosting plan for three or four years upfront, but for most of us, committing to one provider for that long is a lot to ask.
Take a look at monthly and yearly payment options before you make your decision.
Now that you know what to look out for, you’ll be able to get the most bang for your buck. Happy hosting!

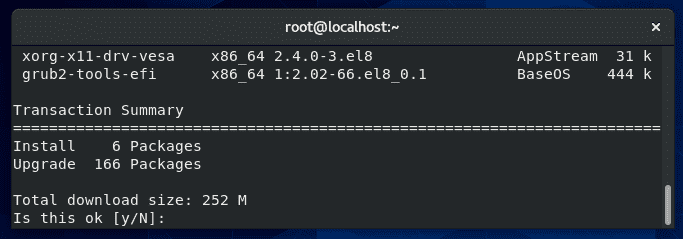
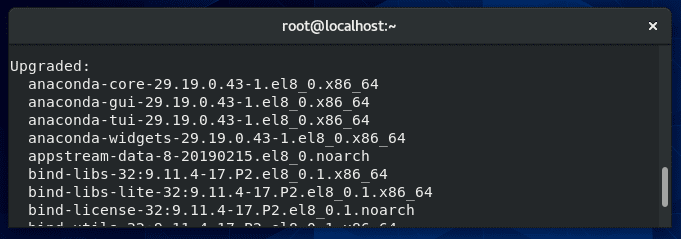
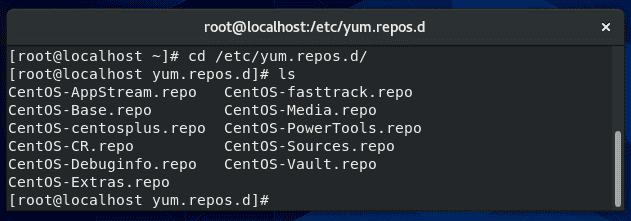
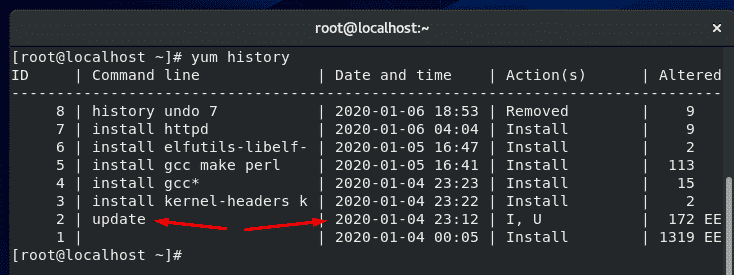
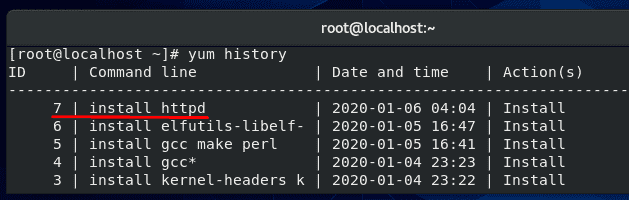
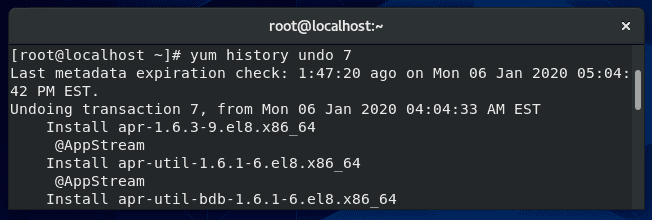
 Yum is a package manager used on Red Hat, CentOS, and other
Yum is a package manager used on Red Hat, CentOS, and other 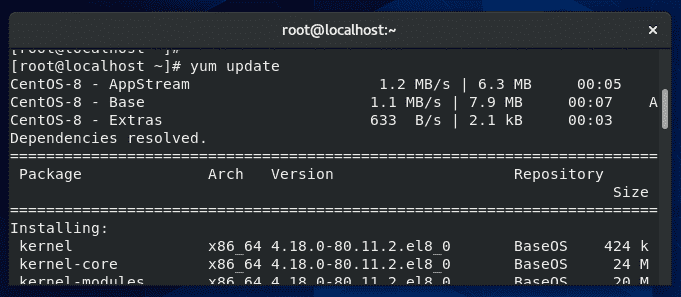

 Matplotlib is a library in python that creates 2D graphs to visualize data. Visualization always helps in better analysis of data and enhance the decision-making abilities of the user. In this matplotlib tutorial, we will plot some graphs and change some properties like fonts, labels, ranges, etc. First, we will install matplotlib, then we will start plotting some basics graphs. Before that, let’s see some of the graphs that matplotlib can draw. There are a number of different plot types in matplotlib. This section briefly explains some plot types in matplotlib. A line plot is a simple
Matplotlib is a library in python that creates 2D graphs to visualize data. Visualization always helps in better analysis of data and enhance the decision-making abilities of the user. In this matplotlib tutorial, we will plot some graphs and change some properties like fonts, labels, ranges, etc. First, we will install matplotlib, then we will start plotting some basics graphs. Before that, let’s see some of the graphs that matplotlib can draw. There are a number of different plot types in matplotlib. This section briefly explains some plot types in matplotlib. A line plot is a simple 














 Writing a research paper is a huge task in itself. When you think about how easy it is for other people to copy or plagiarize the paper you worked hard on, this should encourage you to learn how to protect your research papers and other documents on your Linux computer. To do this, you should improve
Writing a research paper is a huge task in itself. When you think about how easy it is for other people to copy or plagiarize the paper you worked hard on, this should encourage you to learn how to protect your research papers and other documents on your Linux computer. To do this, you should improve 
 Bilindiği gibi,
Bilindiği gibi, 

 Hackers can access, steal and sell your online activity data as well as manipulate it if you don’t use the right system and tools. The level of protection you want will largely influence which tools and systems to use. With a
Hackers can access, steal and sell your online activity data as well as manipulate it if you don’t use the right system and tools. The level of protection you want will largely influence which tools and systems to use. With a  We have all more or less accepted that we are living in some kind of dime-store George Orwell novel where our every movement is tracked and recorded in some way. Everything we do today, especially if there’s any kind of gadget or electronics involved, generates
We have all more or less accepted that we are living in some kind of dime-store George Orwell novel where our every movement is tracked and recorded in some way. Everything we do today, especially if there’s any kind of gadget or electronics involved, generates