In the previous post, we talked about how to Secure Linux Server Using Hardening Best Practices, some people asked me about the firewall section which was a brief introduction about iptables firewall. Today we will discuss in detail the Linux iptables firewall and how to secure your server traffic using that awesome firewall. If you are using CentOS 7, you will find that firewalld was introduced to manage iptables, so if you want to go back to iptables, you have to stop and mask firewalld.
In the previous post, we talked about how to Secure Linux Server Using Hardening Best Practices, some people asked me about the firewall section which was a brief introduction about iptables firewall. Today we will discuss in detail the Linux iptables firewall and how to secure your server traffic using that awesome firewall. If you are using CentOS 7, you will find that firewalld was introduced to manage iptables, so if you want to go back to iptables, you have to stop and mask firewalld.
$ systemctl stop firewalld
$ systemctl mask firewalld
Then install iptables service and enable it:
$ yum install iptables-services
$ systemctl enable iptables
Then you can start it:
$ systemctl start iptables
How Linux Firewall Works
Iptables firewall functions are built on Netfilter framework that is available in the Linux kernel for packets filtering.
Firewall Types
There are two types of firewalls:
Stateless firewall process each packet on its own, it means it doesn’t see other packets of the same connection.
Stateful firewall this type of firewalls cares about all packets passed through it, so it knows the state of te connection. It gives more control over the traffic.
Netfilter contains tables. These tables contain chains, and chains contain individual rules.
If the passed packet matches any rule, the rule action will be applied on that packet.
The actions can be: accept, reject, ignore, or pass the packet on to other rules for more processing.
Netfilter can process incoming or outgoing traffic using the IP address and port number
Netfilter is managed and configured by the iptables command.
Before we start writing firewall commands, we need to understand the firewall structure a bit so we can write firewall rules easily.
iptables Firewall Tables
Netfilter has three tables that can carry rules for processing.
The iptables filter table is the main table for processing the traffic.
The second is nat table, which handles NAT rules.
The third table is the mangle table, which is used for mangling packets.
Table Chains
Each table of the above-mentioned tables contains chains, these chains are the container of the rules of iptables.
The filter table contains FORWARD, INPUT, and OUTPUT chains.
You can create a custom chain to save your rules on it.
If a packet is coming to the host, it will be processed by INPUT chain rules.
If the packet is going to another host, that means it will be processed by OUTPUT chain rules.
The iptables FORWARD chain is used for handling packets that have accessed the host but are destined to another host.
Chain Policy
Each chain in the filter table has a policy. The policy is the default action taken.
The policy could be DROP, REJECT, and ACCEPT.
The ACCEPT policy allows the packets to pass the firewall. The DROP policy drops a packet without informing the client. The REJECT policy also drops the packet and inform the sender.
From a security perspective, you should drop all the packets coming to the host and accept only the packets that come from trusted sources.
Adding iptables Rules
You can add a new rule using the iptables command like this:
$ iptables -A INPUT -i eth1 -p tcp --dport 80 -d 1.2.3.4 -j ACCEPT
Let’s break this command into pieces so we can understand everything about it.
The -A means we are adding a new rule. By default, all new rules are added to filter table unless you specify another table.
The -i flag means which device will be used for the traffic to enter the host. If no device specified, the rule will be applied to all incoming traffic regardless the devices.
The -p flag specifies the packet’s protocol that you want to process, which is TCP in our case.
The –dport flag specifies the destination port, which is 80.
The -d specifies the destination IP address which is 1.2.3.4. If no destination IP address specified, the rule would apply to all incoming traffic on eth1 regardless of IP address.
The -j specifies the action or the JUMP action to do, here we are accepting the packets using the accept policy.
The above rule allows incoming HTTP traffic which is on port 80.
What about allowing outgoing traffic?
$ iptables -A OUTPUT -o eth1 -p tcp --sport 80 -j ACCEPT
The -A flag is used to add rules to the OUTPUT chain.
The -o flag is used for the device used for outgoing traffic.
The -sport flag specifies the source port.
You can use the service name like http or https instead of the numeric port number on sport or dport. The service names can be found in /etc/services file.
It is recommended to use the service name rather than a port number, which makes reading rules easier.
Iptables Rules Order
When you add a rule, it is added to the end of the chain.
You can add it on the top by using -I option.
The sequence of the rules matters as you will see now.
You can insert your rules exactly where you want using the I flag.
Look at the following rules to understand how rules ordering matters:
$ iptables -I INPUT 3 -i eth1 -p udp -j ACCEPT
$ iptables -I INPUT 4 -i eth1 -p udp --dport 80 -j DROP
The first rule accepts all UDP traffic comes to eth1, and the number 3 is the rule order.
The second rule drops the traffic that enters port 80.
The first rule will accept all the traffic, then the second rule will be ignored because the first rule already accepts all the traffic so the second rule here makes no sense.
Your rules should make sense since the order of the rules in the chain matters.
List iptables Rules
You can list the rules in a chain using -L flag:
$ iptables -L INPUT
You can show the line numbers for rules using –line-numbers:
$ iptables -L INPUT --line-numbers
The list shows the services names, you can show port numbers instead using -n option:
$ iptables -L INPUT -n --line-numbers
This will make the listing faster because it prevents iptables from DNS resolution and service lookups.
You can list all rules for all chains like this:
$ iptables -L -n --line-numbers
To get how many packets processed by each rule, you can use the -v flag:
$ iptables -L -v
Also, you can reset the counters to zero using -Z flag.
Now we can add a new rule to any chain we want, we can insert the rule in a specific order and we can list the rules for any chain or all chains, but what about deleting a rule?
Deleting Rules
You can delete a rule using -D flag:
$ iptables -D INPUT -i eth1 -p tcp --dport 80 -d 1.2.3.4 -j ACCEPT
This command will delete the HTTP rule that you specified earlier.
Before you delete a rule, just make sure of the rule specification by listing it, then delete it.
You can delete the rule using the order number instead of writing the rule specifications.
$ iptables -D INPUT 2
You can delete all rules in a specific chain using -F flag which means flush all rules.
$ iptables -F INPUT
If you forget to mention the chain name when using -F flag, then all chain rules will be deleted.
Replacing Rules
You can replace existing rules with your own rule using -R flag:
$ iptables –R INPUT 1 –i eth1 –p tcp —dport httpht –d 1.2.3.4 –j ACCEPT
This command will replace the first rule in INPUT chain with the typed rule.
Listing Specific Table
To list a specific table, use the -t flag with the table name like this:
$ iptables -L -t nat
Here we list the rules in nat table.
Iptables User Defined Chain
To create a user defined chain, use the -N flag.
$ iptables -N MY_CHAIN
Also, you can rename it using -E flag.
$ iptables -E MY_CHAIN NEW_NAME
And you can delete the user-defined chain using -X flag.
$ iptables -X MY_CHAIN
If you don’t mention the chain name when using -X flag it will delete all user-defined chains. You can’t delete built-in chains like INPUT and OUTPUT.
Redirection to a User Defined Chain
You can redirect packets to a user-defined chain like built-in chains using -j flag.
$ iptables -A INPUT -p icmp -j MY_CHAIN
So all incoming ICMP traffic will be redirected to the newly created chain called MY_CHAIN.
Setting The Default Policy for Chains
You can use the -P flag to set the default policy for a specific chain. The default policy could be ACCEPT, REJECT and DROP.
$ iptables -P INPUT DROP
So now the input chain will drop any packet come unless you write a rule to allow any incoming traffic.
SYN Flooding
The attacker sends SYN packets only without completing the TCP handshake and as a result, the receiving host would have many opened connections, and your server becomes too busy to respond to other clients.
We can use the limit module of iptables firewall to protect us from SYN flooding.
$ iptables -A INPUT -i eth1 -p tcp --syn -m limit --limit 10/second -j ACCEPT
Here we specify 10 SYN packets per second only. You can adjust this value according to your network needs.
If this will throttle your network, you can use SYN cookies.
SYN Cookies
In /etc/sysctl.conf file and add this line:
net.ipv4.tcp_syncookies = 1
Then save and reload.
$ sysctl -p
Drop INVALID State Packets
The INVALID state packets are packets that don’t belong to any connection and should be dropped.
$ iptables -A INPUT -m state --state INVALID -j DROP
This rule will drop all incoming invalid state packets.
Drop Fragmented Packets
Fragmented packets are broken pieces of large malformed packets and should be dropped
The -f flag tells iptables firewall to select all fragments. So if you are not using iptables as a router, you can drop fragmented packets.
$ iptables -A INPUT -f -j DROP
Save iptables Rules
All the rules we discussed will be lost if you reboot your server, so how to persist them.
You can save all of your rules using the iptables-save command if you are using CentOS or Red Hat.
iptables-save > /etc/sysconfig/iptables
On CentOS 7, you can save rules like this:
$ service iptables save
You can save specific table like filter table only:
$ iptables-save -t filter
Also, you can use iptables-restore to restore rules that were saved.
On Debian based distros, you can use the iptables-persistent package to save and restore rules.
First, install it:
$ apt-get install iptables-persistent
Then you can save and restore rules:
$ netfilter-persistent save
$ netfilter-persistent reload
I Hope you find iptables firewall easy. Keep coming back.
Thank you.
 In the previous post, we talked about
In the previous post, we talked about 



 In the previous post we talked about some
In the previous post we talked about some 
 In the previous post, we talked about
In the previous post, we talked about 



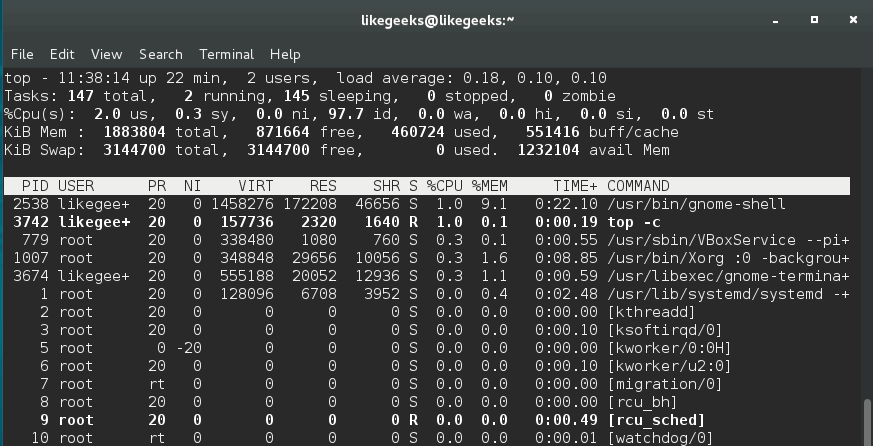
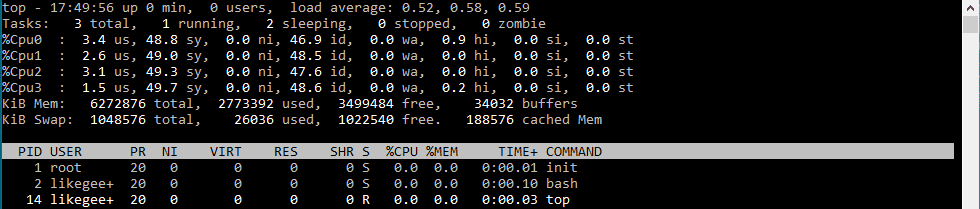
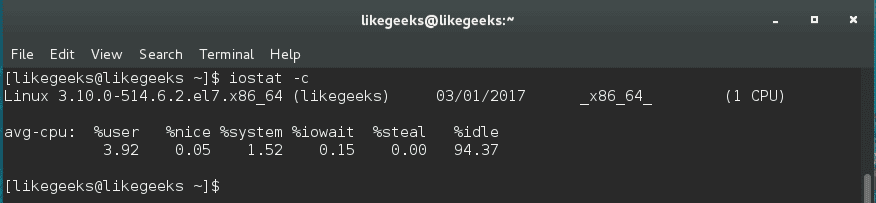
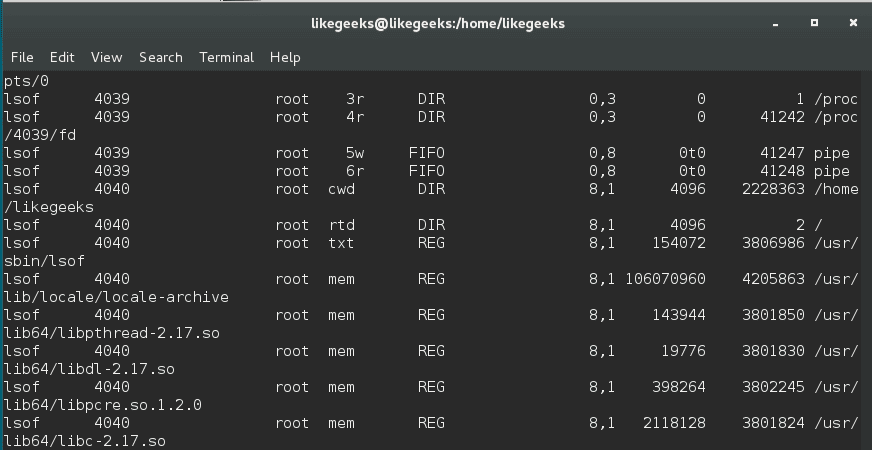
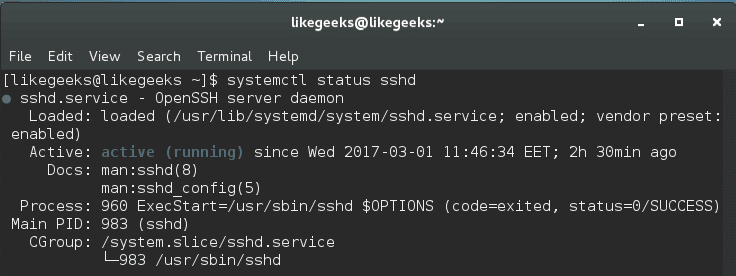
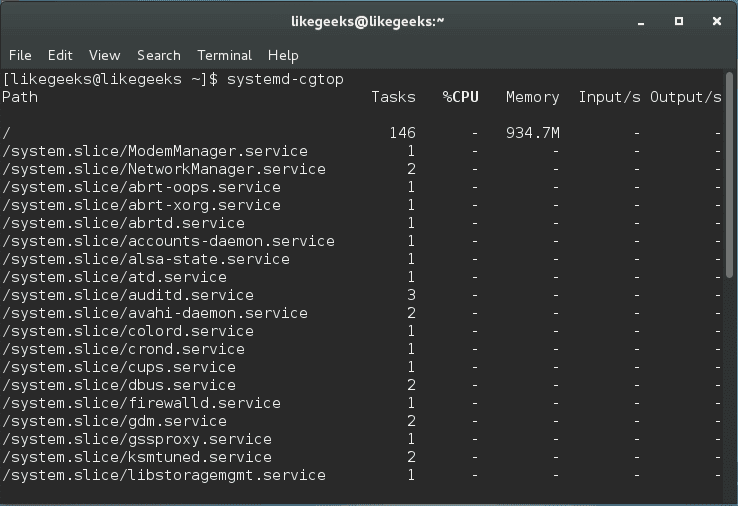
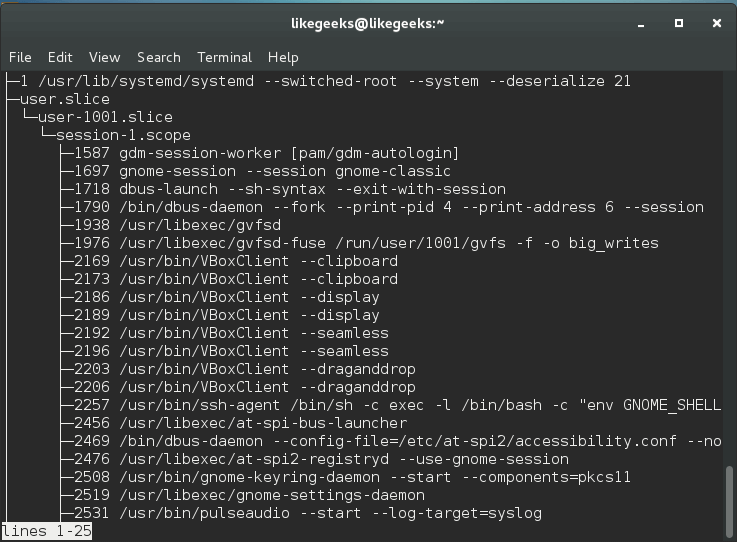
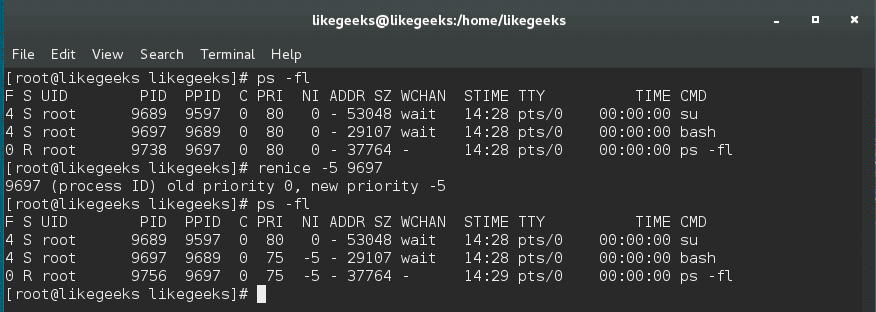
 In server administration, it is very important to understand how the running processes work in detail, from high load to slow response time processes. When your server becomes so slow or fails to respond, you should understand the process management or Linux process management in specific to an action. When it is the time to kill a process or renice it and how to monitor the currently running processes and how these processes affect the system load. Let’s see how Linux process management will help us tune the system.
In server administration, it is very important to understand how the running processes work in detail, from high load to slow response time processes. When your server becomes so slow or fails to respond, you should understand the process management or Linux process management in specific to an action. When it is the time to kill a process or renice it and how to monitor the currently running processes and how these processes affect the system load. Let’s see how Linux process management will help us tune the system.







 The Linux NIS server (Network Information Service) is a server used for sharing critical data stored in flat files between systems on a network, it is often ideal to have a common repository (such as NIS) for storing user and group information that is traditionally stored in flat files like /etc/passwd. So what is the benefit of that? By making such files available via the NIS server, that would allow any remote NIS client machine to access or query the data in these shared files and use them as extensions to the local versions. NIS is not limited to sharing files. Any tabular file which at least has one column with a unique value can be shared via NIS like /etc/services file. The main benefit from using NIS server is that you keep your data and files, and if your data is updated, all updates be propagated to all users. Some users, especially windows users might think this is sort of Active Directory like service, but the Linux NIS server is older than Active Directory and not a replicate for it.
The Linux NIS server (Network Information Service) is a server used for sharing critical data stored in flat files between systems on a network, it is often ideal to have a common repository (such as NIS) for storing user and group information that is traditionally stored in flat files like /etc/passwd. So what is the benefit of that? By making such files available via the NIS server, that would allow any remote NIS client machine to access or query the data in these shared files and use them as extensions to the local versions. NIS is not limited to sharing files. Any tabular file which at least has one column with a unique value can be shared via NIS like /etc/services file. The main benefit from using NIS server is that you keep your data and files, and if your data is updated, all updates be propagated to all users. Some users, especially windows users might think this is sort of Active Directory like service, but the Linux NIS server is older than Active Directory and not a replicate for it. In the previous post, we talked about how to write a
In the previous post, we talked about how to write a